
咨询QQ:2083503238、1684129674、480934277(请勿重复咨询) 咨询微信:qiangfans
快速认识HTTP协议
- 2019-03-30 08:57:00
- 测试帮日记
- 原创 1714 投稿得红包
点击链接加入QQ群229390571(免费公开课、视频应有尽有):https://jq.qq.com/?_wv=1027&k=5rbudQa
一、TCP/IP 协议族
为了使世界上的计算机可以通过网络互相通信,就需要在不同的硬件、软件、操作系统之间制定一种通信规则,这种规则就称为协议(protocol)。
为了实现全球互联网通信,IETF(The Internet Engineering Task Force,国际互联网工程任务组) 对相关的所有硬件和软件制定了一系列标准协议,集合起来总称为「TCP/IP 协议族」,简称「TCP/IP」。
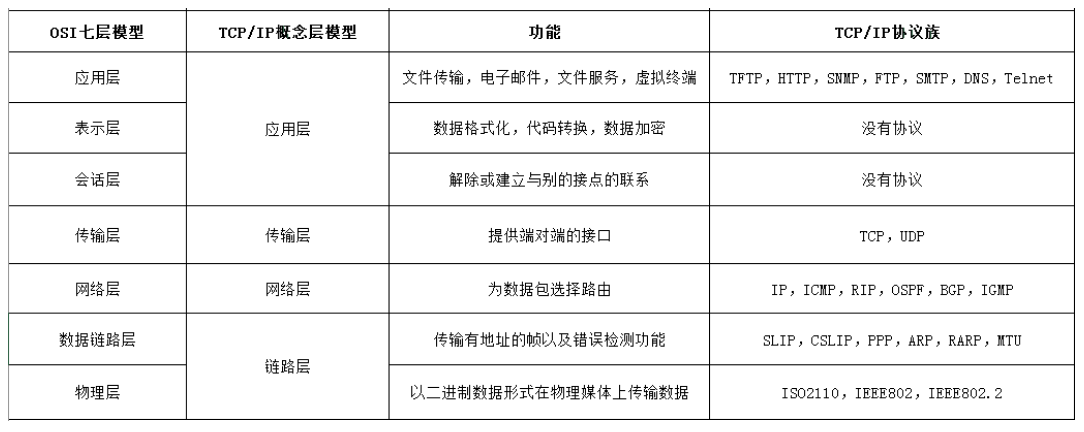
1、分层模型
TCP/IP 四层模型和 OSI 七层模型对比:
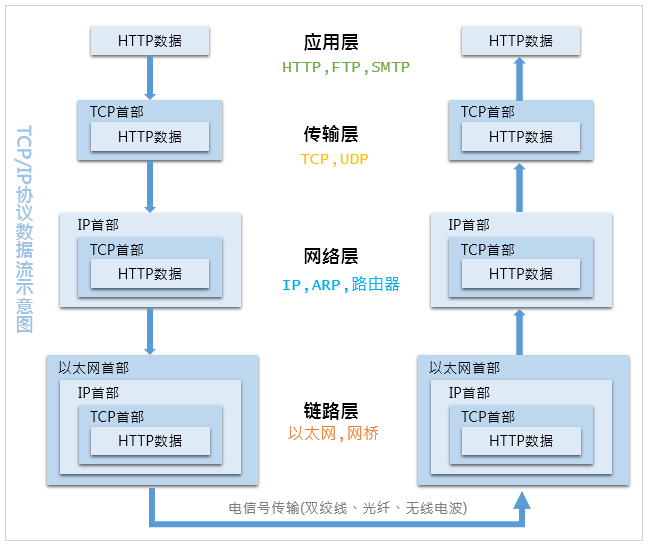
2、数据处理流程
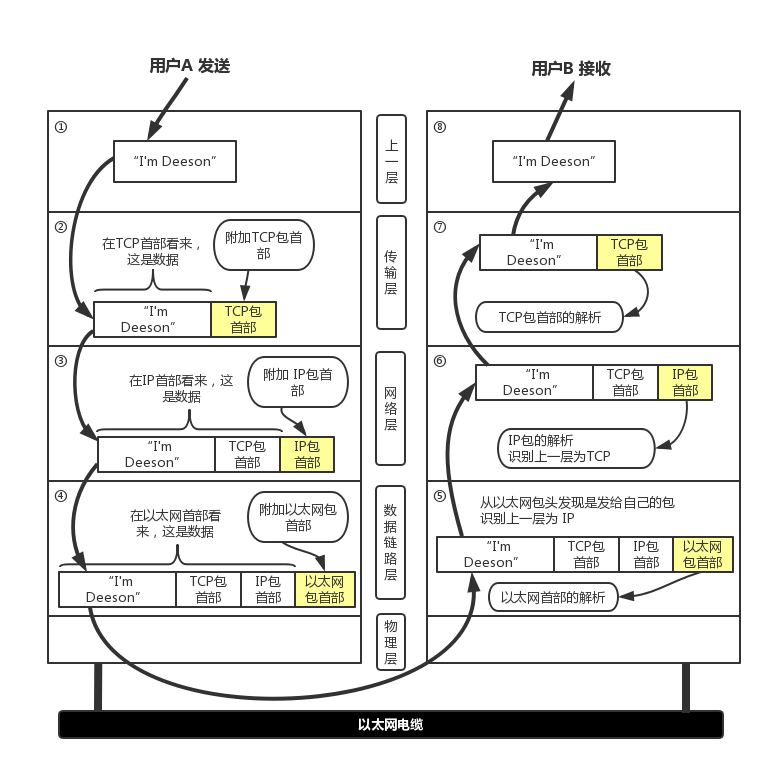
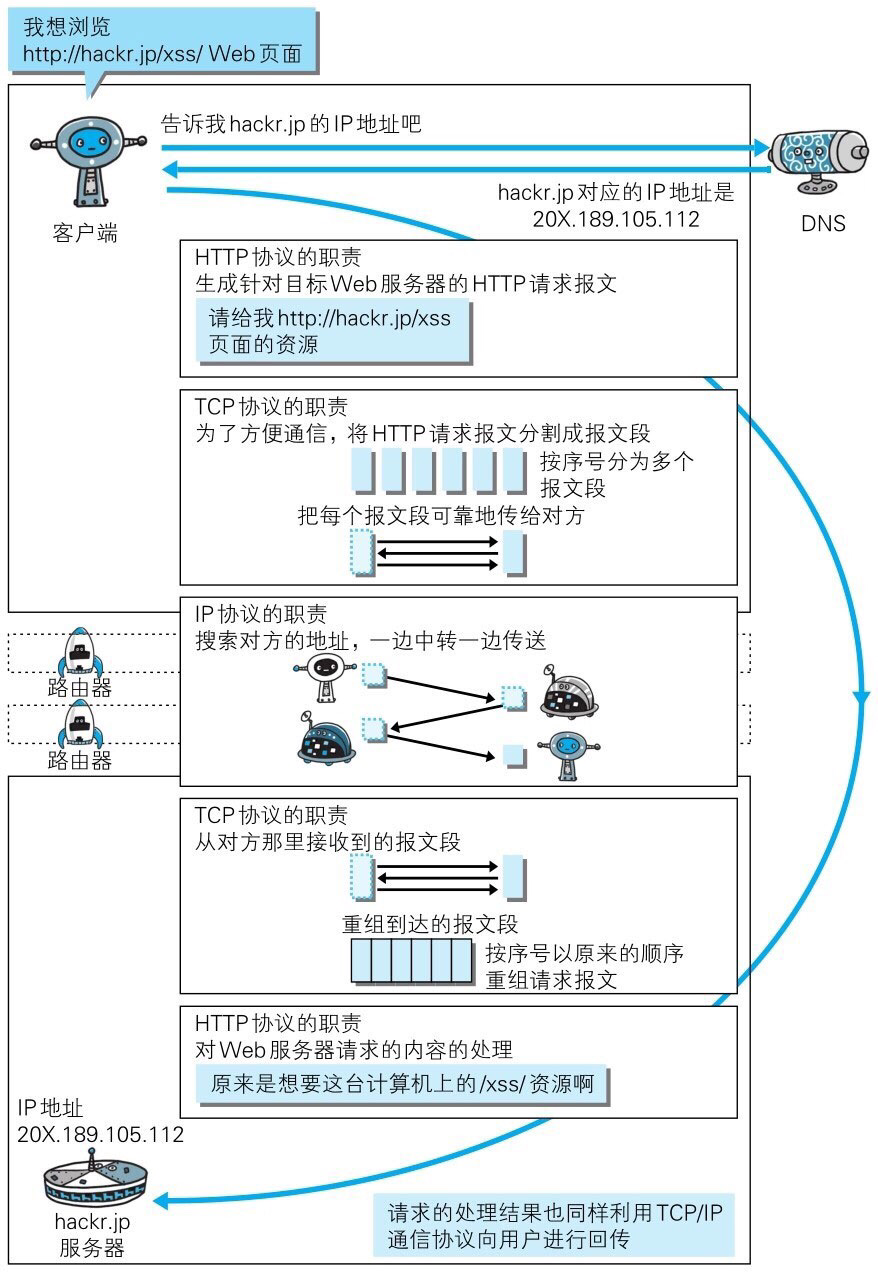
数据在层与层之间传输,发送端每到一层都会对附加一个首部信息,接收端每到一层就会删除一个对应首部,最终拆包出原始数据。
TCP/IP 四层协议处理数据流程:
OSI 七层协议处理数据流程:
3、HTTP 和 IP、TCP、DNS
在 TCP/IP 协议族中,与 HTTP 关系最密切的三个协议就是 IP、TCP、DNS。
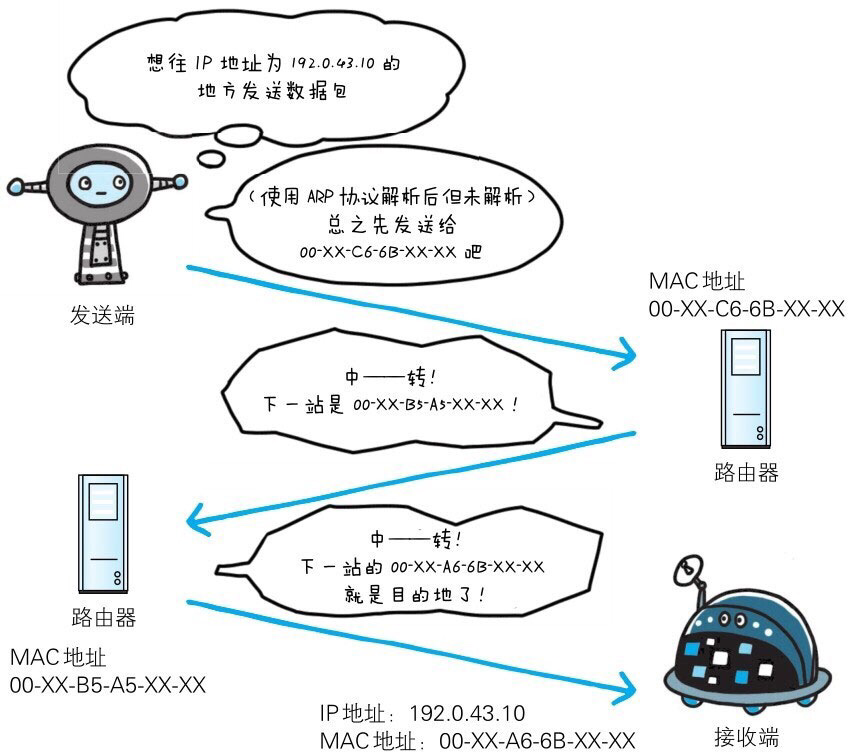
IP 协议:
Internet Protocol 网际协议,位于网络层。
作用是把各种数据包传送给对方。
为保证把数据传送到对方,要满足两个重要的条件:IP地址和 MAC地址。
IP地址指明节点被分配到的地址,MAC地址是网卡所属的固定地址,二者配对。
IP地址可变换,但MAC地址基本不变。
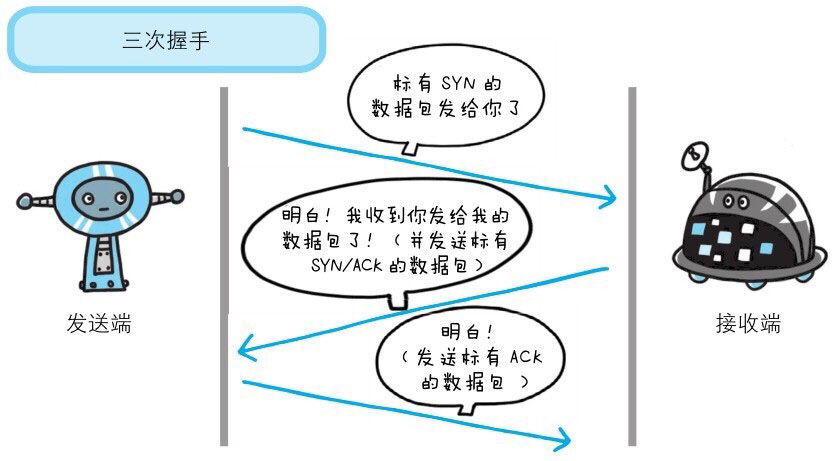
TCP 协议:
位于传输层,提供可靠的字节流服务,确保可靠性
三次握手确保数据能到达目标
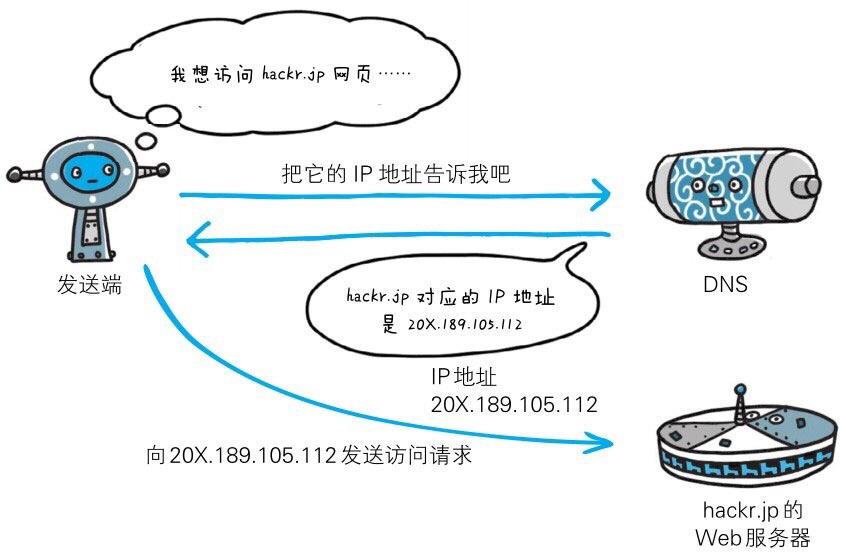
DNS 服务:
Domain Name System,负责域名解析,位于应用层,把域名解析成IP地址
二、HTTP 协议结构
客户端: 请求访问文本或图像等资源的一方
服务器端:提供资源响应的一方
HTTP:(Hyper Text Transfer Protocol) client 和 server 之间传输数据的超文本传输协议。
每个 HTTP 请求和响应都遵循相同的格式,一个 HTTP 包含 Header 和 Body 两部分,其中 Body 是可选的。
1、HTTP 请求报文
HTTP GET 请求格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
HTTP POST 请求格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
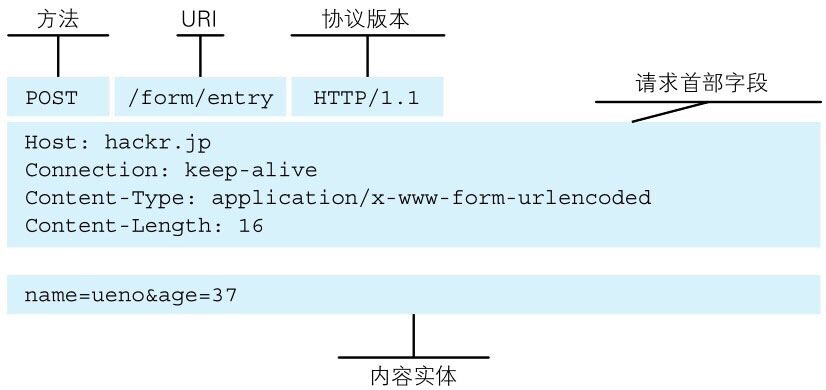
每个 Header 占用一行。
当遇到空行,即连续两个换行符 rn 时,Header 部分结束,后面的数据全部是 Body。
当请求网站首页时,URI 为 /
URI 和 URL
URI:统一资源标识符,用字符串标识某一互联网资源
URL:统一资源定位符,表示资源的地点(互联网上所处的位置),是URI的子集
URI 的格式:

登录信息:可选
服务器端口号:当使用默认端口 80 时,可选
查询字符串:查询指定文件路径时的参数,可选
片段标识符:标记出已获取资源中的子资源(文档内的某个位置),可选
2、HTTP 响应格式
HTTP/1.1 200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...

HTTP 响应如果包含 body,也是通过 rnrn 来分隔的。
2.1 响应码
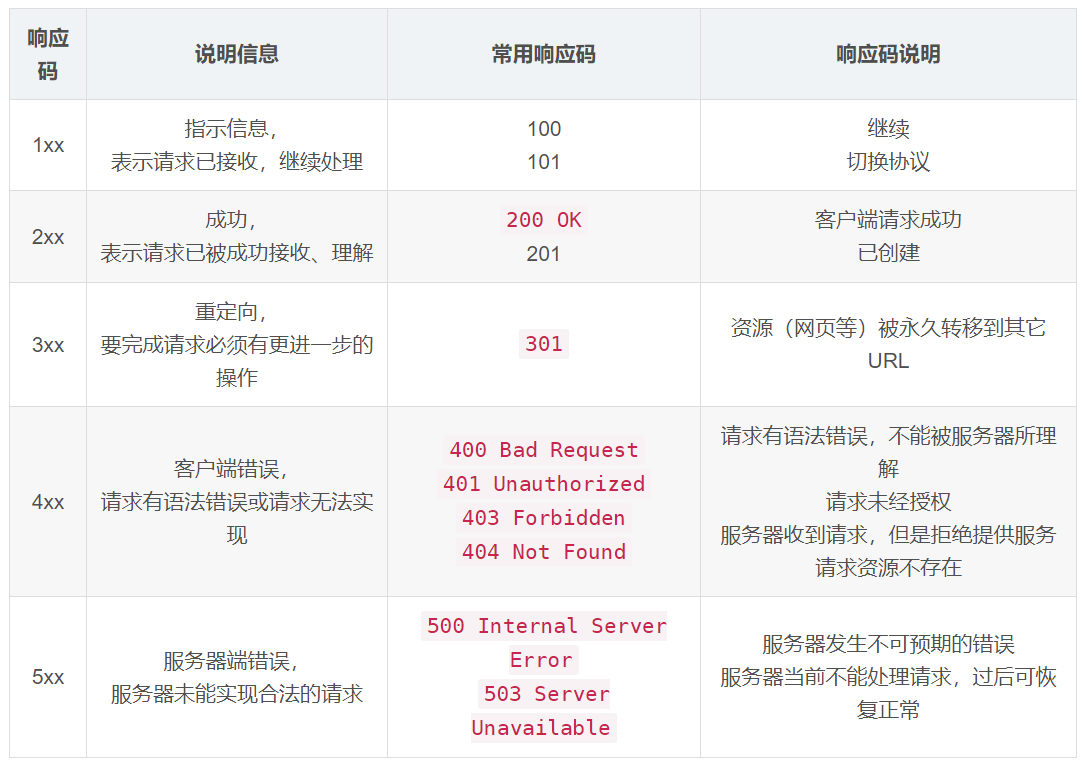
2.2 Content-Type 和 Content-Encoding
Body 的数据类型由 Content-Type 头来确定,而不是 URL
即使 URL 是 http://www.baidu.com/meimei.jpg,也不一定就是图片。
Content-Type:text/html;charset=utf-8:响应内容是网页,编码是UTF-8
Content-Type:image/png:响应内容是图片
Content-Encoding: gzip:说明 Body 数据是被压缩的,压缩方式是 gzip
要先将数据解压缩,才能得到真正的数据
压缩的目的在于减少Body的大小,加快网络传输
3、查看 HTTP 报文
我们可以通过很多工具来查看 client 和 server 之间的报文传输情况,也就是常说的 「抓包」。
这里以 Chrome 浏览器为例进行简单的抓包说明:
在 Chrome 地址栏输入 www.sina.com ,浏览器将显示新浪首页
通过 Chrome - F12 - Network 查看 client 和 server 之间的通信过程
点击 Name 为 www.sina.com 的记录,查看右侧的 Request 和 Response 的 view source 内容。
Chrome F12 说明:
Elements: 网页结构
Console:控制台输出信息
Source:资源文件
Network:浏览器和服务器的所有通信记录
Headers:显示请求头、请求体和响应头信息
view source:显示浏览器和服务器之间的原始/实际通信内容
Response:显示响应体内容
4、HTTP 请求流程
还是以访问新浪首页为例,总结一下 HTTP 请求的流程:
1、 client 向 server 发送 HTTP 请求
请求包括:方法,URI,域名,其它 headers,使用POST方法时还包括 Body
2、 server 向 client 返回 HTTP 响应
响应包括:响应码,响应类型,其它 headers,响应 Body
3、 若 client 还要向 server 请求其它资源(如图片),则再次发送 HTTP 请求,重复步骤 1、2。
浏览器解析过程:
当浏览器读取到新浪首页的 HTML 源码后,它会解析 HTML 并显示页面,
然后,根据 HTML 里面的各种链接,再发送 HTTP 请求给新浪服务器,拿到相应的图片、视频、Flash、JavaScript脚本、CSS等各种资源,
最终显示出一个完整的页面,所以我们在 Network 下面能看到很多额外的 HTTP 请求。
HTTP 协议具备极强的扩展性,虽然浏览器请求的是新浪首页 http://www.sina.com,但是新浪可以在响应的 HTML 中链入其他服务器的资源,比如<img src="https://n.sinaimg.cn/index/mid_article/images/ask.png">,从而将请求压力分散到各个服务器上。
并且一个站点可以链接到其他站点,无数个站点互相链接起来,就形成了 WWW(World Wide Web) 。
三、HTTP 版本发展

1、HTTP 1.0
主要缺点:
短连接,一个连接只能有一个请求,即每次请求都会重新建立一个 TCP 连接
TCP 建立连接需要三次握手,加上慢启动的特性,这将是很耗资源和性能的一步
解决办法:
部分 HTTP 1.0 的实现版本,在请求头中添加了一个 Connection:keep-alive标记
该标记要求服务器不要关闭 TCP 连接,以便其他请求复用。服务器同样回应这个字段。
直到客户端或服务器主动关闭连接。
但是,这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法,并没有被广泛支持。
2、HTTP 1.1
HTTP 1.1 版本中引入了很多优化技术,这是到目前为止使用最广泛的版本,但是大部分服务器也支持1.0版本。
2.1 持久连接
最大的变化就是引入了持久连接(HTTP persistent connection或HTTP connection reuse)。
特点:
TCP 连接默认不关闭,可以被多个请求复用
只要任意一端没有明确提出断开连接,则保持连接状态。
建立一次 TCP 连接后,可以进行多次请求和响应交互
减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻服务器负载,使 web 页面显示速度更快。
目前,对于同一个域名,大多数浏览器允许同时建立 6 个持久连接。
2.2 管道机制
在持久连接的基础上还引入了管道机制(pipelining)。
特点:
在同一个 TCP 连接里面,客户端可以同时并行发送多个请求,而不用等待前面请求的响应,进一步提升效率。
之前版本中,发送一个请求后要等待并收到响应,才能发送下一个。
2.3 Content-Length 字段
在管道机制中,一个 TCP 连接同时发送多个请求,服务器依次处理并返回响应。
为了准确区分响应数据包是属于哪一个请求的,在响应头中加入 Content-length 字段,声明本次响应的数据长度。
在 1.0 版中,浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。
如 Content-Length: 3495 表示本次回应的长度是 3495 个字节,后面的字节就属于下一个回应了。
2.4 分块传输编码
使用 Content-Length 字段的前提是,服务器发送回应之前,必须知道回应的数据长度。
对于一些很耗时的动态操作、或者传输大量数据时,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。
更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer),使浏览器逐步显示页面。
因此,1.1 版本又引入了 “分块传输编码”(chunked transfer encoding)。只要请求或响应的头信息有 Transfer-Encoding 字段,就表明回应将由数量未定的数据块组成。
Transfer-Encoding: chunked
每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了,例如:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
This is the data in the first chunk
1C
and this is the second one
con
sequence
2.5 队头堵塞
虽然 1.1 版本允许复用 TCP 连接,但是同一个 TCP 连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。
要是前面的回应特别慢,后面就会有许多请求排队等着。这称为"队头堵塞"(Head-of-line blocking)。
为了避免这个问题,只有两种方法:
一是减少请求数
二是同时多开持久连接。
对应的,需要做很多网页优化工作,比如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等等。
2.6 Cookie 机制
Cookie 技术最早是在 1994 年由 Netscape 公司的一名员工提出的,最终在 2011 年才被 IETF 正式纳入规范中。
HTTP 无状态特点:
无状态: stateless
HTTP 协议自身不对请求和响应之间的通信状态进行保存
简单,方便,不保存客户端状态,减少服务器 CPU 及内存消耗
缺点:
对于要求登录认证的网站,为了使服务器识别登录信息,需要在每次请求报文中附加一些信息,在连接较多时会增加带宽压力。
为了在特定场景中实现保持状态的功能,引入了 Cookie 技术来实现状态的管理。
Cookie 机制:
client 发出请求后,server 返回响应,并在响应报文中加入 Set-Cookie 字段,用于通知 client 保存 Cookie。
client 收到响应后,把 Set-Cookie 字段以文本保存在本地
client 再次向 server 发送请求,并在请求报文中加入 Cookie 字段。
server 收到带 cookie 的请求,比对服务器记录,得到之前的状态信息。


